데이터 모델이란?
현실 세계의 정보나 데이터를 시스템으로 구축하기 위해 추상화하여 체계적으로 표현한 모형
데이터 모델링이란?
영속성을 갖는 데이터에 대한 시스템 구조를 사람이 이애할 수 있도록 형상화하는 과정
*용어 구분
ER : 엔티티 간의 관계
ER모델 : ER을 표현한 것
ERD : 엔티티 간 관계를 그림으로 표현
*Entity(엔티티) : 속성들의 집합
ER 모델의 구성요소
- 엔티티(Entity)
- 관계(Relationship)
- 속성(Attribute)
- 식별자(Identifier)
엔티티(Entity)
정의)
엔티티란? 데이터의 집합이다. 쉽게 말해서 업무를 구현하는 데 필요하고 관리해야 하는 주체, 대상, 행위 등의 모든 집합적인 것(Thing)으로 정의할 수 있다.
특징)
1. 적어도 둘 이상의 인스턴스가 존재할 수 있어야 한다.
2. 최소한 둘 이상의 속성이 있어야 한다.
3. 반드시 각 인스턴스를 식별할 수 있는 속성이나 관계가 하나 이상 정의되어야 한다.
4. 해당 업무에서 필요하고 관리하고자 하는 정보이어야 한다.
엔티티의 확장)
슈퍼타입 엔티티 : 하나 이상의 서브타입 엔티티와 관계된 일반화된 엔티티
서브타입 엔티티 : 각각의 서브 타입에만 존재하는 고유한 속성을 관리하며, 슈퍼타입의 식별자, 속성, 관계 등 모든 특성을 상속받는다.
- 일반화
- 엔티티 각각이 가지고 있는 고유한 특징을 일반화하여 공통의 속성으로 재정의한 것
- 보편적인 의미보다는 공통적인 의미에 더 가깝다.
- 두 개 이상의 하위 수준 엔티티를 결합하여 상위 수준의 엔티티로 통합하는 상향식 접근 방식

- 특수화
- 하나의 상위 수준 엔티티를 두 개 이상의 하위 수준 엔티티로 분할하는 하향식 접근 방식

관계(Relationship)
관계는 관계수, 선택성, 식별성, 관계명 등으로 구성된다.

| 구성요소 | 설명 |
| 관계수 (cardinality) |
어떤 엔티티의 인스턴스 하나가 다른 엔티티 몇개(1, m) 인스턴트와 대응될 수 있는지를 표시한 것으로, 상대 엔티티 쪽에 까마귀 발(Crow's Foot)로 표시한다. 최대 인스턴스 수와 관련이 있다. ex) 1:1, 1:M, M:N |
| 선택성 (optionality) |
해당 엔티티 인스턴스에 대해 상대 엔티티에 인스턴스가 반드시 존재해야 하는지(Mandatory), 존재하지 않아도 되는지(Optional) 표시한다. 최소 인스턴스 수와 관련이 있다. ex) 양쪽 필수, 한쪽 필수, 양쪽 선택 |
| 식별자 상속 (Identifier Inheritance) |
엔티티 간의 관계를 정의하면서 엔티티의 식별자를 다른 엔티티에서 상속받을 때 식별자로 상속받을지(식별관계), 일반 속성으로 상속받을지(비식별관계) 표시한다. |
| 관계명 (Relationship Name) |
관계의 의미나 이름을 표시한다. 의미를 명확하게 표시한다는 측면에서 양쪽에 모두 기술하기도 하며, 관계선만으로도 의미가 통하는 경우 이름을 생략해도 무방하다. ex) 관계 유형 - 기본 관계, 재귀적 관계, 병렬 관계, 슈퍼타입/서브타입 관계 |
* 관계(교차) 테이블은 언제 사용할까?
① m:n 관계 해소
② 병렬 관계 해소
속성(Attribute)
- 데이터를 표현하는 가장 작은 단위
- 속성이 가지는 의미를 통해 엔티티 특성이나 상태를 알 수 있음.
- 하나의 엔티티는 두 개 이상의 속성을 가지며, 속성명, 식별자여부(PK), 옵셔널리티(Null/Not Null), 도메인(데이터 혀식과 범위) 등으로 구성
속성의 분류)
| 단순 속성 | 속성을 더 분해할 수 없는 원 값을 갖음 |
| 복합 속성 | 단순 속성들의 조합 |
| 저장 속성 | 원래 존재하는 속성 ex)상품단가, 주문 수량, ... |
| 파생 속성 | 저장 속성이나 다른 파생 속성으로부터 파생된 속성(저장되어 있지 않은 속성) ex) 상품단가*주문수량 |
| 단일 값 속성 | 성별, 생일처럼 사원에 대해 하나의 값만 가지는 속성 |
| 다중 값 속성 | 하나의 속성이 여러 개의 값을 가지는 속성 |
식별자(Identifier)
엔티티에서 인스턴스를 개별적으로 식별할 수 있는 속성(들)
식별자의 특징)
- 유일성(Uniqueness) : 사원 엔티티의 사원번호 속성처럼 엔티티의 모든 인스턴스를 유일하게 식별할 수 있어야 함.
- 최소성(Minimum) : 식별자를 구성하는 속성은 유일성을 만족하는 최소 속성들로 구성해야 함. (부서코드+사원번호 또는 사원번호 속성으로 유일한 경우 최소성의 원칙에 따라 사원번호 속성을 식별자로 함)
- 불변성(Stability) : 일단 엔티티의 식별자를 지정하면 그 식별자의 값은 변하지 않아야 함
- 존재성(Mandatory) : 모든 직원은 사원번호를 가지 듯이 식별자는 반드시 데이터 값이 존재해야 함.
- 고유 식별 여부
- 본질 식별자 : 업무에서 일반적으로 통용되는 식별자 ex) 주민등록번호, 사원번호
- 인조 식별자 : 업무에서 사용하진 않지만, 데이터를 효율적으로 관리하기 위해 별도로 추가한 식별자 ex) 주문일련번호, 입출급일련번호
- 대표성 여부
- 주 식별자
- 대체(보조) 식별자
* 어떤 본질 식별자 또는 인조 식별자가 주 식별자일 때 다른 본질 식별자는 대체 식별자가 됨
관계형 데이터 모델
릴레이션의 구성


키 종류)
| 슈퍼키 (Super Key) |
튜플을 고유하게 식별 할 수 있는 속성 집합을 말한다. 릴레이션은 한 개 이상의 슈퍼키를 가질 수 있으며, 슈퍼키 값은 모든 튜플에서 유일해야 한다. |
| 후보키 (Candidate Key) |
튜플을 고유하게 식별 할 수 있는 최소한의 속성 집합을 후보키라고 한다. 후보키는 유일성과 최소성을 가진다. |
| 기본키 (Primary Key) |
릴레이션은 하나 이상의 후보 키가 있을 수 있으며 그 중 하나만을 기본키로 선택할 수 있다. 후보키와 마찬가지로 유일성, 최소성을 가진다. |
| 대체 키 (Alternate Key) |
후보키 중에 기본키가 아닌 후보 키가 대체키에 해당한다. |
| 외래키 (Foreign Key) |
어떤 릴레이션의 어트리뷰트 값이 다른 릴레이션에 속한 어트리뷰트의 기본키를 참조하는 경우를 말한다. |

제약조건)
- 키 제약조건 : 키는 튜플을 유일하게 식별할 수 있는 어트리뷰트들로 구성하며, 다른 튜플의 키 값과 중복된 값이 있어서는 안된다.
- 실체 무결성 : 릴레이션의 기본키를 구성하는 모든 어트리뷰트는 Null 값이 아니어야 하고, 릴레이션 내에서 오직 하나의 값만 존재해야 한다.
- 영역 무결성 : 릴레이션 내의 각 어트리뷰트 값은 반드시 정의된 도메인에 속한 값이어야 한다.
- 참조 무결성 : 자식 릴레이션의 외래키는 참조하는 부모 릴레이션의 기본키 값 이외의 값을 가질 수 없으며, 두 릴레이션 값의 일관성을 유지해야 한다.
함수 종속
관계형 데이터베이스를 설계할 때 정규화 과정을 거치게 되는데 이 때 함수 종속성(어떤 기준으로 쪼갤 것인가) 개념이 중요하게 사용된다.
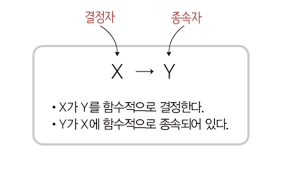
| 완전 함수종속 | 릴레이션에서 속성 집합 Y가 속성 집합 X에 함수적으로 종속되어 있지만, 속성 집합 X의 전체가 아닌 일부분에는 종속되지 않음을 의미. Y는 X에 대하여 완전 함수 종속성을 갖는다. ex) 당첨여부는 {고객아이디, 이벤트 번호}에 완전 함수 종속됨 |
| 부분 함수종속 | 릴레이션에서 속성 집합 Y가 속성 집합 X의 전체가 아닌 일부분에도 함수적으로 종속됨을 의미 ex) 고객 이름은 {고객 아이디, 이벤트 번호}에 부분 함수 종속됨 |
| 이행적 함수종속 | 함수 종속 관계 X → Y와 Y → Z가 성립되면, 논리적 결과로 X → Z가 성립한다. 이 때 속성 Z는 X에 이행적 함수 종속성을 갑는다. |
정규화
- 데이터를 입력, 수정, 삭제할 때 발생하는 이상 현상을 최소화하기 위해 좀 더 작은 단위의 테이블로 설계하는 과정
장점)
- 데이터를 입력, 수정, 삭제하는 과정에서 발생하는 이상 현상을 최소화할 수 있다.
- 상호 종속성이 강한 데이터 요소들을 분리하여 독립된 개념(엔티티)으로 정의함에 따라 높은 응집력과 낮은 결합도 원칙에 충실하면서, 데이터 구조 변경 시 유연성이 증가한다.
- 개념을 좀 더 작은 단위로 세분할 경우 해당 개념에 대한 재활용성이 높아진다.
- Non-key 데이터 요소가 한 번만 표현됨에 따라 중복을 최소화하고, 데이터 품질 문제를 줄일 수 있으며, 저장공간을 최소화 할 수 있다.
- 데이터 입력, 수정, 삭제에 대한 작업을 최소화하여 수행속도가 향상된다.

[참고]
<핵심 데이터 모델링 - 유동오 저>
'공부 > 데이터 베이스' 카테고리의 다른 글
| <핵심 데이터 모델링> - 논리 모델링 (0) | 2024.07.01 |
|---|---|
| <핵심 데이터 모델링> - 개념 모델링 (0) | 2024.07.01 |
| [데이터 베이스] 3장_데이터베이스 시스템 (0) | 2021.10.08 |
| [데이터 베이스] 2장_데이터베이스 관리 시스템 (0) | 2021.10.07 |
| [데이터 베이스] 1장_데이터베이스 기본 개념 (0) | 2021.10.07 |



